pluton's blog
blog about me
Sandisk Sansa Clip+ + podcasts + gPodder
Hello everybody!
I’ve been using a Sandisk Sansa Clip+ 4GB player for a few months now. It’s an excellent player for podcasts. It is definitely a bang for the buck. A big advantage is that it saves the position of each podcast when you switch to another one.
The player has a menu item called Podcasts, where it places all recognized podcasts from the internal memory. When I first uploaded podcasts to the device, I wasn’t very happy because podcasts’ tags are filled differently. The player builds the list based on the Artist field, and the second level is the Title tag. I wanted to use the menu correctly, so I had to create a script to fix the tags.
Git repository with the script is available here: https://github.com/pluton8/fixtags. You can clone it or just download the script by pressing the Download button on that page. So, you’ve downloaded and unpacked it. Let’s assume you’ve placed it to your ~/bin/ directory. How to run it?
You need to install Python 3 and a package called stagger (http://code.google.com/p/stagger/) first.
Luckily, gPodder supports running a custom script after downloading a podcast. We’ll use the feature. Actually, the script can’t be run outside of gPodder. In gPodder go to Preferences, then push the “Edit config” button. There is a field named “cmd_download_complete”, which specifies a command being run after downloading a file. Insert the path and filename of the script to that field. Here is a screenshot:
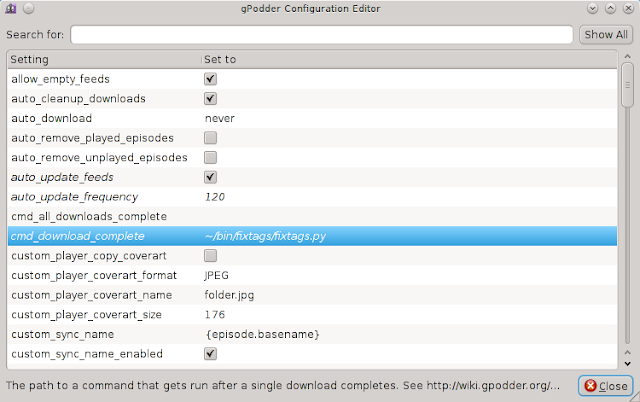
In my case, the script is sitting in the directory bin/fixtags/ in my home directory. Save the config. Now the script should work.
NB! The script processes the podcasts it knows only! That is, the ones I added support for. If you listen to other podcasts, you will have to update the script.
That’s all. Feel free to ask any specializing questions.



Hi! I found you through Google-fu while trying to make my Clip+ work better. Unfortunately, I’m not a programmer or anything of the like. Could you explain something for me, please…?
About this script… I’m not sure where the ~/bin folder you alluded to is. You also said that the script couldn’t be used outside gPodder. Does that mean it can’t be used with a similar program, like Juice? Juice allows running a command after a download’s completed (screenshot: http://postimage.org/image/10lamsxvo/).
I’m also curious about why Python and stagger are necessary… but that’s probably a big question.
Thanks for your time.
~Ian
Hi Ian. Thanks for your reply! Sure, I’ll try to help you with this stuff.
By the “~/bin” folder I mean “bin” directory in my home folder. But that could be any other dir.
Yes, the script is designed to be used with gPodder, because it uses specific variables set by gPodder. Since Juice similarly allows running an arbitrary command, the script could be adapted for it. Unfortunately, there is no version for Linux, so I don’t use it. If you want to try my script, I can suggest that you check out gPodder.
I use Python, because the script is small and simple and Python is suitable for the task. Of course, it can be written in any other language. stagger adds support of mp3 tags manipulation, which is the main point here.
Thanks for the post! I used it for a while and then played with it some. Not sure if my way is any better, but it uses only bash and eyeD3. I use the “after download” feature in gpodder options like you showed.
I run eyeD3 against any mp3 files that don’t make it into a good podcast folder after sync’ing. Then I update the version of the ID3 tags and set any options that look like they need a value. The ones that seem to give the player a problem are Album, artist, Genre, and title (-A, -a, -G, -t). Each podcast that I subscribe to has to have a separate “cd” and “for” loop. This example shows only 2 of the podcasts that I subscribe to.
I keep a “last-run” timestamp set in the gpodder directory so I won’t reset files that have already been fixed. If you keep resetting them, they will never be recognized as “old” by gpodder during its cleanup routine.
#! /bin/bash
GPODDER_HOME=$HOME/gpodder-downloads
TIMESTAMP_FILE=$GPODDER_HOME/time_anchor
echo $GPODDER_HOME
# each call to fixtag executes something like – – –
# eyeD3 –to-v2.4 -A ‘Reality Check’ -a ‘Ottawa Skeptics’ -G ‘Podcast’ -t ‘RealityCheck’ *mp3
# Elucidations_ A University of Chicago Podcast
cd $GPODDER_HOME/Eluci*
for name in `find ./ -name ‘*.mp3’ -cnewer $TIMESTAMP_FILE`
do
eyeD3 –to-v2.4 $name
done
# State of Belief
cd $GPODDER_HOME/State*
for name in `find ./ -name ‘*.mp3’ -cnewer $TIMESTAMP_FILE`
do
eyeD3 –to-v2.4 -A ‘StateOfBelief’ -a ‘StateOfBelief’ -G ‘Podcast’ -t ‘StateOfBelief’ $name
done
rm $TIMESTAMP_FILE
touch $TIMESTAMP_FILE
Thanks for the comment, Mark.
Actually, eyeD3 is written on and uses Python, as well as my solution.
I’ve been using my script for a year now, gradually polishing it, and it works great. Except for the case when an episode doesn’t have any tags, but the script expects them there. I monitor this situations with the log file.